The Importance of Data Migration Anomalies
In terms of data migration an “anomaly” is usually a case of a source data internal inconsistency or where there is insufficient information for a record to be migrated with confidence and some human intervention is recommended. Nearly all GIS datasets have anomalies of one kind or another. And data anomalies particularly present themselves during the time of a data migration – it’s a time when we look at our data more intently and more critically than almost any other time.
Anomalies != QA Errors
Anomalies should not be confused with QA errors. QA errors exist in all GIS datasets. They are relatively straightforward to identify – though not always straightforward to resolve. An example of a QA error would be a case where a three phase overhead transformer feature that is expected to have three related transformer unit records in fact has two. Another QA error would be a case where a transformer unit has a KVA rating of 7, but the value 7 is not in the KVA coded value domain. Resolving our first QA error is relatively simple – since we know there should be three transformer unit records for a three phase transformer and there are only two we can add a third unit record. Resolving the second QA error is not so simple. Are there in fact 7 KVA transformers in our system and the domain needs to be expanded? Or is 7 in fact an invalid KVA value, and if so, what is the correct KVA? This error requires research to resolve.
Example 1
If anomalies are not QA errors then what are they? Well, they may be described best by example. Consider this case. Our source gas distribution data has fittings, including transition fittings (fittings that join pipes of different materials) that are not snapped to pipes.
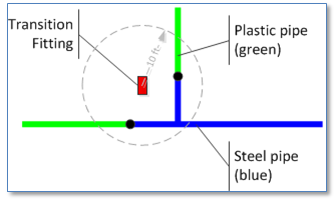
However we want the migration process to snap these fittings to junctions that fall within 10 feet of the fitting where a steel main connects to a plastic main and there is no other fitting present. This may generally be a good rule to follow in a migration process, but we would also need to account for cases than aren’t handled neatly by our rule, such as the case where there are more than one junction of a steel and plastic pipe within our ten foot radius. There is information available during our automated migration process that’s not typically available, yet there is not enough information to apply our migration rule.
Example 2
Consider another case where we’re migrating fiber optic equipment and there are two primary sources, one being a CAD drawing with cable and device locations and a second being a set of spreadsheets with properties of those cables and devices. Neither source is considered to be more authoritative than the other.
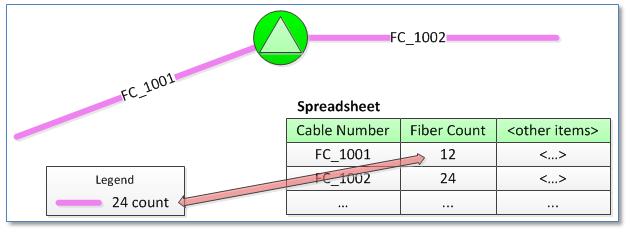
The fiber count present in each cable is indicated by a particular color or layer name in the CAD drawing and also by a column in the cable spreadsheet. In at least some cases when we find mismatches between the CAD entity and the spreadsheet record. We can’t discard the fact that there is a discrepancy between these sources.
Anomaly Management
Both cases described would be considered to be “anomalies”. Cases where the migration process cannot provide a definitive, high-confidence result but for which some human intervention may be required. In these cases we would typically create “anomaly features” as either point or line features in distinct anomaly feature classes that include a reference to both the source and target records and additional descriptive information about the anomalous condition. Here are example records we might create to document the anomaly cases described above.

Anomaly record created for transition fitting

Anomaly record created for fiber cable
The timing and effort invested to resolving anomalies can be determined as part of the data migration planning. Anomalies can also be categorized and prioritized so that, for example, any anomaly conditions deemed ‘critical’ can be resolved before migrated data is put into production while others can be resolved during normal data maintenance activities. In either case, if we’ve tracked anomaly conditions during the migration process we’ve set ourselves on a path for improving data quality – and improving the value of our GIS to the whole organization.
