ArcGIS/ArcFM Dirty Feeder Detection
Let’s lay the groundwork here. The term “dirty feeder” stems from the concept of a dirty area which is an efficient method for change detection and used for applications such as document management or software version management. In a version management system there may be thousands versions of a document but there are not thousands of replicas of the document – rather each “version” stores just those changes (dirty areas) that make it different from its parent. Why its pre-supposed that the parent is “clean” and a child has made some changed area “dirty” I can’t really say, though I wouldn’t be surprised if the term’s coiner was adjusting to a newborn.
That behind us, we’ll go forward with the notion that a “dirty” electric distribution feeder is one that has been changed in some way and has yet to be validated as correct – or is different in the GIS that in a client application fed from the GIS.
Why it can be quite useful to know about these things is largely rooted in the need to deliver feeder definitions to non-GIS systems. The electric GIS typically provides an authoritative representation of the normal state of the electric network to other analytical applications, such as OMS, DMS, system planning and others.  Data is extracted from the GIS and provided in some type of interchange format. In the best cases updates from the GIS are exchanged on a daily basis, though weekly updates are not unusual.
Data is extracted from the GIS and provided in some type of interchange format. In the best cases updates from the GIS are exchanged on a daily basis, though weekly updates are not unusual.
The “extraction” process is however not instantaneous.
Say it takes 30 seconds to export a feeder, including the time required to select/trace its extent, gather features from the result and format them into your export data structure – be it CIM, Multispeak or proprietary. 30 seconds per feeder would be pretty good. But if you’ve got 1,000 feeders then the full process would take 500 minutes/8.3 hours. And if your export takes a minute per feeder the process jumps to 16+ hours of processing time.
If you can run a 8 to 16 hour process at the frequency you need an export – or if your feeder count times average processing time fits in your available window – then stop reading now. There’s no point in adding extra complexity to your life.
The rest of this discussion will assume you can’t reasonably process all feeders as often as you need.
What Makes a Feeder Dirty?
In the simplest case, any add/change or delete of a feature that has a FEEDERID field would cause a feeder to be considered “dirty”. In practice this approach would in many cases flag more feeders as dirty than you would really want. Here are examples of edits that might not pass muster in flagging a feeder:
• An update to any attribute that’s not significant to your analysis application, such as an update to a COMMENTS field.
• An update to a street light where you have street lights in the GIS network but your analysis application doesn’t.
• An update to a subtype in a feature class that’s not significant to your analysis application, for example an update to an arrester the MiscNetworkFeature class where the FaultIndicator subtype is significant but Lightning Arrester not.
• An update to a feature geometry in the GIS but your analysis application is non-graphic.
Of course these are just examples. Yours will vary.
Detection Approaches
A dirty feeder detection process has got to be automated. With the variety of ways that features can get updated in your ArcGIS/ArcFM implementation users may not always be aware of edits made to feeders as a result of their individual edits. Here are several ways detection can be done.
Detection On Feature Edit
The ArcGIS Editor fires an event on every edit (add, change or delete) made to a feature or object. Within an ArcFM implementation these edits can be trapped and handled using AutoUpdaters assigned to Geodatabase classes. In general, this method involves creating AutoUpdaters that listen for a feeder edit and when found write a record to the dirty feeder table. In this case we’d want to have the dirty feeder table versioned so edits wouldn’t be seen by the extraction process until the version is posted to DEFAULT. The diagram below illustrates the general process.
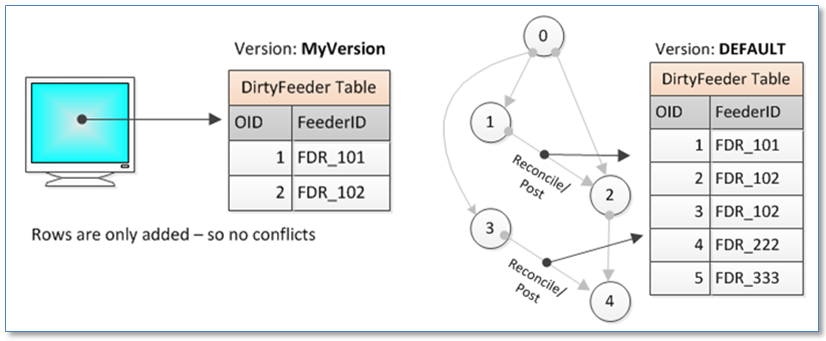
The extraction process would be responsible for looking for unique FEEDERID values in the table and deleting all rows with the FEEDERID value on completion.
This method has the following pros and cons:
• The method would be sure to capture all feeder edits with little chance of any edit falling through the cracks, though the table might grow quite large in size
• Every edit to a feature would be captured, even if the same feature is updated multiple times in the same version
• Logic would be added impacting the performance all edit operations on all feeder features – even those edit operations that are eventually undone or when multiple operations are performed on a feature
• Even though processing of the table would be simple – there should be no chance of conflict since rows are only ever added to the table – it would add another table to be managed by your versioning scheme
Detection on Version Reconcile
In a versioned Geodatabase every edit made in a user version is evaluated when that version is reconciled with a parent version. Similar to edit events, the OnReconcile event provides another opportunity to detect changes to a feeder. Logic would be added as added as a “Workspace Extension” to ensure it fired whenever a reconcile was performed – either within a user’s edit operation or under control of some automated reconcile process, such as that provided by Schneider Electric’s GDBM product. The diagram below illustrates the process.
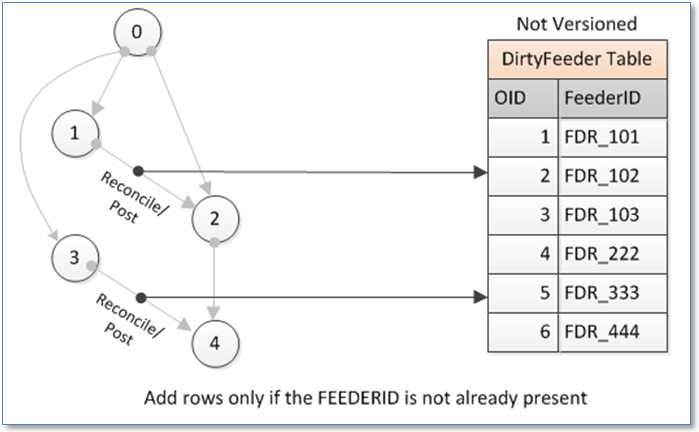
This method offers the following characteristics:
• Change detection logic would not impact normal editing operations – rather similar logic would fire only when the version is reconciled
• Logic would only be applied to the final, saved version of a feature – the attributes of which might be the result of multiple individual edit operations
• Use of OnReconcile detection alone will track edits for reconciles between all versions. An implementation would likely look for only those cases where a child version is reconciled with DEFAULT
Detection using MM_EDITED_FEATURES
ArcFM Feeder Manager 2.0 (FM 2.0) maintains an in-memory only representation of feeders rather than updating FeederID fields on new or updated features. However, FM 2.0 also provides an option to “synchronize” edits to FeederID values when a version is reconciled with SDE.DEFAULT. With this option enabled FM 2.0 records edits to all features with a FEEDERID field in an un-versioned ArcFM system table named MM_EDITED_FEATURES with the following columns:

A set of edited features is maintained by an ArcFM AutoUpdater named “ArcFM Feeder Cache Maintenance” and records are written from the cache to the MM_EDITED_FEATURES table when a “Save” is performed. Edits are only those significant to a feeder definition – for example, an update to “DATEMODIFIED” field only would not cause a record in this table to be created. When the version is posted to DEFAULT these records are then used to update FeederID field values directly in the DEFAULT version. When the version is deleted rows for the version are removed from the MM_EDITED_FEATURES table.
Here are some characteristics of this approach:
• A significant advantage of this method is that if you’re running FM2.0 much of the heavy lifting has been done already. MM_EDITED_FEATURES has your raw material ready for mining.
• To take advantage of information in MM_EDITED_FEATURES a process would need to be initiated after the version was reconciled and before it was deleted. The process would scan the contents of the table for records in the posted version, find FeederID values for each record and update the dirty feeder table.

Dirty Feeder Data Structures
The complexity of your dirty feeder data structure will determined by the number and expectations of client applications that will operate with this data. Generally this would be a table within your Geodatabase. The purpose of the dirty feeder table will simply be to hold a record of whether a particular feeder is currently considered to be “dirty.”
Here are some options.
Single Column Table
In this, the simplest case, the dirty feeder table has a single column, for example:
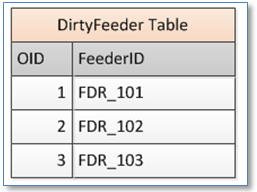
• If the feeder name is present in the table the feeder will be considered “dirty”
• When all operations that need to process dirty feeders are complete the record for that feeder is deleted
• If there is a single application relying on the dirty feeder table this would be the simplest and most straightforward approach to the data structure.
Dated (Historical) Table
If more than one extract application is accessing the dirty feeder table then we would need more than a single FEEDERID column. One option would be a table with columns for feeder name and date/time on which the feeder was discovered to be “dirty.” For example:
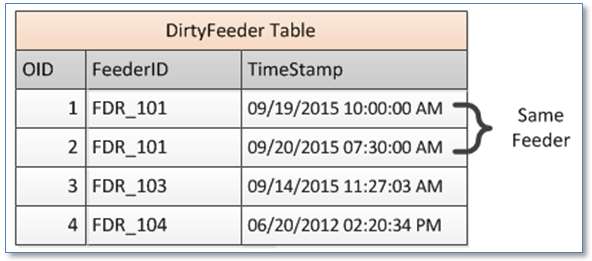
• If the feeder name is present in the table the feeder will be considered “dirty” as of the date/time stamp. An application reading data from the table would need to track the date/time of the last successful operation and ignore records prior to that date/time.
• Dirty feeder detection processes would only ever add a row to the table if the feeder is not already present in the table or if the date is later than any date/time for that feeder. Any change detection process would need to establish a single time at the outset to ensure multiple records were not created for the same feeder seconds or fractions of a second apart.
• Records would never be deleted from this table. Or if they were then records would be deleted as an administrative operation for rows with a date/time stamp prior to the last successful client application completion.
• The number of records that would accumulate in this table might be considerable.
Application Tagged Table
Another way to address the case where there are multiple extract applications is to use a table with columns for feeder name and flags for each client application dependent on the table. For example:

• If the feeder name is present in the table and the client application flag is set to FALSE then that feeder will be considered “dirty” for the purposes of the particular client application. If the feeder name is present in the table and the client application flag set to TRUE then that application will have processed the feeder and it will considered not dirty.
• Dirty feeder process detection would add a row to this table if no row is already present for the feeder. If a row is already present then all client flag values should be set to FALSE.
• When all client application flags are TRUE, then the row should be deleted either by the client application or by an administrative process.
• There will never be more rows in this table than the total number of feeders in the system.
Summary
So, it should be clear at this point that there’s more than one way to do this. And the best way for you will depend on your database size and complexity, the number of client applications to be fed and, probably, other processes you’ve got running in your system. Hopefully the options presented here will help guide you to a solution that works for your company.
